Strus Pattern
Description
StrusPattern is an event-driven pattern detection library for
text processing with a competitive performance, suitable for processing large sets of patterns.
It can be used for detecting multipart entities or structures in text.
The basic tokens are either terms of the analyzer output or entities recognized with regular
expressions.
The Intel hyperscan library
StrusPattern uses the hyperscan
library from Intel for matching regular expressions.
Thanks to Intel for publishing this great work as open source.
Links to alternative solutions
The following links show alternatives for pattern detection in documents.
- CoreNLP, a tool suite for different aspects of NLP, including pattern matching on text, licensed under GPLv3. API available for Java. Stanford CoreNLP covers much more than simple pattern matching. It provides a workbench for all aspects of natural language processing accompanied by a huge knowledge base on the topic.
- https://github.com/mit-nlp
- The Uima Ruta workbench for rule-based text annotation, licensed under the Apache license. APIs available for Java and C++. With Uima Ruta you get a framework to define arbitrary rules on text with its connectors to the big Apache universe for scalable data processing.
Operators
StrusPattern defines patterns as an expression tree of nodes. Each node represents a basic token in the source or operators on tuples of nodes. Most of the operators supported are named according to the posting join operators in the strus query evaluation. Not all of them are implemented though and some exist in StrusPattern, but not in this form in the query evaluation:
Token pattern matching operators
- any: Matches if any of the argument subexpressions or tokens matches.
- and: Matches if all of the argument subexpressions or tokens match with the same ordinal position.
- sequence: Matches if the argument subexpressions or tokens appear in the order as the arguments within a proximity range of ordinal positions specified.
- sequence_imm: Same as 'sequence', but the elements have no gaps in between. No gap means that the start ordinal position of the follower element in the sequence is the end ordinal position of the predecessor.
- sequence_struct: Matches if the argument subexpressions or tokens appear in the order as the arguments within a proximity range of ordinal positions specified without a structure delimiter (e.g. end of sentence token), specified as the first argument, within the span of a match.
- within: Matches if the argument subexpressions or tokens appear in arbitrary order within a proximity range of ordinal positions specified.
- within_struct: Matches if the argument subexpressions or tokens appear in arbitrary order within a proximity range of ordinal positions specified without a structure delimiter (e.g. end of sentence token), specified as the first argument, within the span of a match.
Example
The following example illustrates how StrusPattern works.
Example patterns defined
Define the patterns in a text file
We define the example rules defined in the following listing in a file "example.rul".
The declarations with an identifier followed by a ':' specify the tokens defined by regular expressions. The counting of the different token start positions defines the ordinal positions of the tokens. The number following a '^' after the name of the token defines its level, a sort of prioritization. Tokens covered completely by a token of a higher level are not part of the output and for ordinal position assignments. We use the possibility to supersede rules. In our example we define a hierarchy SENT (end of sentence) < ABBREV (abbreviation) < URL < EMAIL. It means that a dot is an end of sentence marker if not part of an abbreviation, URL or email address. An abbreviation is not recognized as such if part of an URL. An URL is not an URL, if part of an email address, etc.
The declarations with an identifier followed by a '=' specify the patterns defined on tokens with an ordinal number of appearance as a position for proximity range specifications.
WORD ^1 :/\b\w+\b/;
SENT ^2 :/[.]/;
ABBREV ^3 : /\b[aA]bbr[\.]/ | /\b[aA]d[cjv][\.]/ | /\b[oO]bj[\.]/ | /\b[pP]seud[\.]/
| /\b[tT]rans[\.]/ | /\b[A-Za-z][\.][a-z][\.]/ | /\betc[\.]/ | /\bca[\.]/
| /\b[mM]rs[\.]/ | /\b[pP]rof[\.]/ | /\b[rR]ev[\.]/ | /\b[hH]on[\.]/ | /\b[hH]rs[\.]/
| /\b[A-Za-z][btlsr][\.]/ | /\b[gG]en[\.]/ | /\b[sS]ing[\.]/ | /\b[sS]yn[\.]/
| /\b[aA]ve[\.]/ | /\b[d]dD]ept[\.]/ | /\b[eE]st[\.]/ | /\b[fF]ig[\.]/ | /\b[iI]nc[\.]/
| /\b[oO]z[\.]/ | /\b[nN]o[\.]/ | /\b[sS]q[\.]/ | /\b[aA]ssn[\.]/ | /\b[tT]rans[\.]/
| /\b[A-Z][\.]/
;
ABBREV ^4 : /\bet\sal[\.]/ | /\b[rR][\.][iI][\.][pP]\b/;
URL ^5 : @([^\s/?\.#-][^\s/?\.#-]+\.)(aero|asia|biz|cat|com|coop|edu|gov|info|int|jobs|mil|mobi|museum|name|net|org|pro|tel|travel|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cx|cy|cz|cz|de|dj|dk|dm|do|dz|ec|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mn|mn|mo|mp|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|nom|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ra|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|xyz|ye|yt|yu|za|zm|zw|arpa)@;
URL ^6 : @\b(https?://|ftp://)?([^\s/?\.#-]+\.)([^\s/?\.#-]+\.)([a-z]{2,6})(/[^\s]*)?@;
EMAIL ^7 : /\b([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})\b/;
CAPWORD ^1 : /\b\p{Lu}\p{Ll}*\b/;
LOWORD ^1 : /\b\p{Ll}+\b/;
Name = sequence_imm( firstname=CAPWORD, surname=CAPWORD | 2 );
Name = sequence_imm( firstname=CAPWORD, surname=ABBREV | 2 );
Name = sequence_imm( Name, surname=CAPWORD | 10 );
Contact = sequence_struct( SENT, Name, email=EMAIL | 10 );
A "Name" is defined as a sequence of two words with capitalized first letter in a proximity distance of 2 (ordinal position distance).
A "Contact" is defined as a sequence of a name as we defined it and an email address in a proximity
distance of maximum 10 tokens, without an end of sentence marker appearing in between a candidate match.
Apporximative matching with an edit distace
You can also do approximative matching with strusPattern. If you specify a pattern with an operator '~' followed by a positive number after the regular expression defining a token, all tokens within this edit distance of the expression are output as matching tokens. Example:
John : /[Jj]ohn/ ~1; Samuel : /[Ss]amuel/ ~1; Kawelaschwili : /[Kk]awelaschwili/ ~2;
It is recommended to carefully choose the edit distance. The number of matches will explode with a value that is too high. You also have to consider if approximative matching is really needed to solve your problem. The matching process will be totally different with only one pattern defined with edit distance. Hyperscan, the library used for matching the tokens, is not capable of matching edit distance in Unicode characters beyond Ascii. Well, it can run on the data, but matches the edit distance in bytes and not in chatacters. This is no problem when seeking exact matches, but is most likely not what you want when matching Unicode text. StrusPattern supports approximative matching of Unicode strings. It solves the problem by mapping all characters to an artificial one byte character set before matching (therefore loosing some information and making the hyperscan regular expression matcher a guesser). The result candidates extracted are post-filtered with libtre processing the original Unicode string. The difference of character codes in sequences of natural languages in phonetic scripts seems to be discriminating enough for the solution to preform well. This has been shown in a real project with non trivial data.
Exported rules vs. private rules
All results of rules are appearing in the output by default. You can specify a rule to be private with a leading '.' in front of the name. Example:
.Year = sequence_imm( WORD "in", WORD "the", WORD "year", year=NUMBER) ["{year}"];
Event = sequence_imm( when=Year, WORD "something", WORD "happened" ) ["{when}"];
Formatting pattern matcher results
The result value of a pattern or a subexpression matched can be defined with by a format string in square brackets ('[' ']'). The following example patterns shows the handling of money amounts with currencies in patterns:
AMOUNT^3 : /\b[0-9]{1,3}'[0-9]{3,3}'[0-9]{3,3}\b/;
AMOUNT^2 : /\b[0-9]{1,3}'[0-9]{3,3}\b/;
AMOUNT^1 : /\b[0-9]{1,3}\b/;
CURRENCY_CHF : /\b[Ss]{0,1}[Ff][Rr][.]{0,1}\b/;
CURRENCY_EUR : /\b[Ee][Uu][Rr][.]{0,1}\b/;
Currency = CURRENCY_CHF ["CHF"];
Currency = CURRENCY_EUR ["EUR"];
MoneyAmount = sequence_imm( value=AMOUNT, currency=Currency) ["{currency} {value}"];
The pattern format strings ["CHF"] and ["EUR"] refer to constants, where ["{currency} {value}"] substitutes two variables of the subexpressions of the patterns. An input "3'645 Eur" would generate a value "EUR 3'645" in this example. For lexems there are no format strings possible in the grammar.
Define the patterns in C++
No documentation available yet.
Define the patterns in Python
No documentation available yet.
Example input
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <doc> <text>This is an example document about Prof. John P. Doe, contact mail@etc.com, or visit www.etc.ch. He is responsible for development, etc.. </text> </doc>
Tokenization
We call the program strusPatternMatch with the following command line:
strusPatternMatch -K -p examples/config/program1.rul examples/data/input.xml
The option -K tells the program also to print the tokens recognized. The following output shows the tokens recognized with our set of patterns defined:
1: WORD This 1: CAPWORD This 2: WORD is 2: LOWORD is 3: WORD an 3: LOWORD an 4: WORD example 4: LOWORD example 5: WORD document 5: LOWORD document 6: WORD about 6: LOWORD about 7: ABBREV Prof. 8: WORD John 8: CAPWORD John 9: ABBREV P. 10: WORD Doe 10: CAPWORD Doe 11: WORD contact 11: LOWORD contact 12: EMAIL mail@etc.com 13: WORD or 13: LOWORD or 14: WORD visit 14: LOWORD visit 15: URL www.etc.ch 16: SENT . 17: WORD He 17: CAPWORD He 18: WORD is 18: LOWORD is 19: WORD responsible 19: LOWORD responsible 20: WORD for 20: LOWORD for 21: WORD development 21: LOWORD development 22: ABBREV etc. 23: SENT .
Rule matching
As output of our command line call we get also the entities recognized with our example patterns:
examples/data/input.xml: Name [8, 108]: surname [9, 113, 2] 'P.' firstname [8, 108, 4] 'John' Name [8, 108]: surname [10, 116, 3] 'Doe' firstname [8, 108, 4] 'John' surname [9, 113, 2] 'P.' Contact [8, 108]: email [12, 129, 12] 'mail@etc.com' firstname [8, 108, 4] 'John' surname [9, 113, 2] 'P.' Contact [8, 108]: email [12, 129, 12] 'mail@etc.com' surname [9, 113, 2] 'P.' firstname [8, 108, 4] 'John' surname [10, 116, 3] 'Doe' OK done
Performance measurements on an Intel NUC (NUC6i3SYK)
The following runs show the behavior of the StrusPattern pattern matching without tokenization. We just use random documents represented as Zipf distributed random numbers, assuming 30'000 different terms in the whole collection. Each document contains 1000 such terms.
The patterns are sequences of two random terms (Zipf distribution applied here too) within a proximity range of 1 to 10 with smaller proximity being much more likely than larger proximity conditions.
We start 4 threads with the same pattern set with different input documents and test with 10 to 10'000'000 patterns evaluated.
This test does not help to estimate the performance of the system solving a real world problem. But it can help to estimate its behavior when confronted with real world problems, if you look at the numbers in detail, like how many patterns were activated or how many patterns matched, etc.. Leaving the regular expression matching out in this test is not a problem since you can for sure assume, that the ultra fast hyperscan library from Intel will not be a bottleneck.
For real world problems, you also have to take into account, that patterns get more complicated, with subexpressions, more complex operators than a simple sequence and variables assigned for items, you want to be part of the result. The numbers here are just representing the numbers for a set of the simplest type of pattern possible. If you measure the performance for pattern nodes detecting sequences of terms or subexpressions within the same sentence, you will roughly double the execution time. Same for nodes detecting the appearance of two features in whatever order compared with a simple sequence.
If you have more complex patterns, e.g. expression trees with many nodes, you have to count every node as a unit and you have to take into account that every subexpression matched produces an event that gets part of the input processed.
The tests were run on an Intel NUC (NUC6i3SYK), a system with 4 GB RAM is enough for processing the test with 10'000'000 nodes.
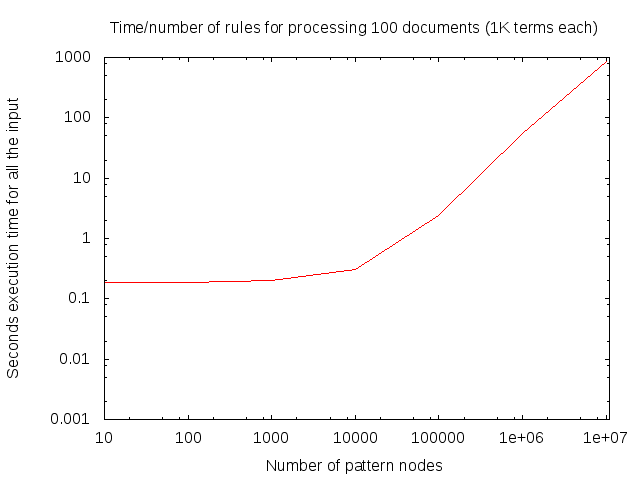
for dd in 10 100 1000 10000 100000 1000000 10000000; do src/testRandomTokenPatternMatch -t 4 -o 30000 25 1000 $dd sequence; done starting 4 threads for rule evaluation ... OK processed 10 patterns on 100 documents with total 0 matches in 185 milliseconds statistiscs: nofAltKeyProgramsInstalled: 0 nofProgramsInstalled: 491 nofTriggersAvgActive: 0 nofSignalsFired: 491 starting 4 threads for rule evaluation ... OK processed 100 patterns on 100 documents with total 17 matches in 188 milliseconds statistiscs: nofAltKeyProgramsInstalled: 0 nofProgramsInstalled: 33967 nofTriggersAvgActive: 1 nofSignalsFired: 33984 starting 4 threads for rule evaluation ... OK processed 1000 patterns on 100 documents with total 6153 matches in 198 milliseconds statistiscs: nofAltKeyProgramsInstalled: 2035 nofProgramsInstalled: 169880 nofTriggersAvgActive: 6 nofSignalsFired: 174716 starting 4 threads for rule evaluation ... OK processed 10000 patterns on 100 documents with total 55236 matches in 306 milliseconds statistiscs: nofAltKeyProgramsInstalled: 30437 nofProgramsInstalled: 1987366 nofTriggersAvgActive: 84 nofSignalsFired: 2023920 starting 4 threads for rule evaluation ... OK processed 100000 patterns on 100 documents with total 655431 matches in 2418 milliseconds statistiscs: nofAltKeyProgramsInstalled: 360835 nofProgramsInstalled: 20092579 nofTriggersAvgActive: 848 nofSignalsFired: 20545764 starting 4 threads for rule evaluation ... OK processed 1000000 patterns on 100 documents with total 6277057 matches in 55087 milliseconds statistiscs: nofAltKeyProgramsInstalled: 4194327 nofProgramsInstalled: 198949620 nofTriggersAvgActive: 8465 nofSignalsFired: 202923433 starting 4 threads for rule evaluation ... OK processed 10000000 patterns on 100 documents with total 61650742 matches in 844535 milliseconds statistiscs: nofAltKeyProgramsInstalled: 42381393 nofProgramsInstalled: 1990633664 nofTriggersAvgActive: 84649 nofSignalsFired: 2028410811
Interpretation
- processed N patterns on 100 documents with total X matches in T milliseconds:
- N: Number of patterns, sequences of two tokens in an ordinal position distance of 1 to 10 (possibly with unspecified tokens appearing in between) defined
- X: Total number of matching token sequences in 100 documents
- T: Execution time for processing all 100 documents
- nofAltKeyProgramsInstalled: Tells how many optimized patterns with an alternative key event were triggered for execution by a key event during the whole processing of the 100 documents. A pattern is optimized, if an initial token, triggering the evaluation of the pattern, is statistically appearing too often. In this case, a valuable alternative token, if it exists, is chosen, and the initial token event is replayed for the pattern to match. The intention of this optimization is to reduce the number or hits and the following processing of rules that may not match. As an example consider a rule like "The world", that is triggered by every appearance of "the". Triggering the rule with "world" is better in English text.
- nofProgramsInstalled: Tells how many patterns were triggered for execution by a key event during the whole processing of the 100 documents.
- nofTriggersAvgActive: Tells how many patterns were active (waiting for events to complete the pattern match) in average for every input token processed.
- nofSignalsFired: Tells how many signals were fired during the whole processing of the 100 documents. An active pattern listens for signals fired on a slot. The pattern matches a completion condition on the slot.
Performance measurement plot
The following plot shows the measured execution time against the number of sequence rule nodes evaluated.
Open problems and bugs
within and within_struct greediness
Patterns with the operator within or within_struct currently do not work correctly, if
accepted sets of subexpressions are not disjunct. This is due to the greediness of the algorithm,
that does not follow alternative paths or backtrack. To illustrate the problem, have a look at the
pattern matching the elements "AB" and "A" in any order and the source "ABA". The current situation
is that the pattern matcher recognizes "A" as "A" and does not accept a signal for "AB" anymore at the
same position for this pattern.
There are straightforward solutions to this problem, but we did not find yet a good one.
We are aware of this problem and we know that it cannot be neglected.
Currently, you have to formulate your 'within' rules as all possible permutations of sequences
(2 patterns "((A B) A)" and "(A (A B))", if you have 'within' rules with non-disjunct accepted sets.
Sequences do not have this problem.
Symbols and identifiers
It does not make sense to implement every symbol or identifier as an item in the regular expression automaton. For representing ordinary words, we need the possibility to declare identifiers in our rule language. The CharRegexMatchInstanceInterface already has a method to declare such a symbol with the method defineSymbol. But this is one feature not tested yet and not available in our example language.
Testing
We tested the token pattern matching of StrusPattern with randomly generated rules on randomly generated documents verified with an alternative implementation. The test program can be run manually
cd tests/randomExpressionTreeMatch src/testRandomExpressionTreeMatch 100 100 100 100 ./And the differences can be inspected with a diff of the res.txt with the exp.txt file. Currently, the tests fail because of small differences due to the problems with operators on subexpressions with non-disjunct sets of accepted input. We are working on the problem.
Caveats
StrusPattern handles events immediately when they are seen.
This can lead to anomalies when formulating restrictions, e.g. with 'sequence_struct' or 'within_struct'
in cases, the structure delimiter gets the same ordinal position assigned than another token that is part of the
pattern. When the last element of a rule is detected without passing over a structure element, that is part of
the restriction condition, then the result is emitted, even if a restriction event with the same ordinal position,
that should overrule the decision, happens thereafter. Another anomaly of this kind can happen when the
restricting element of a rule occurs with the same position, but before the key event triggering the pattern.
Practically we do not see too bad consequences of this behavior because structure delimiters usually get their
own ordinal position assigned. But it might be needed in the future to treat these cases differently.
At the moment we just mention the expected behavior.
Resume
StrusPattern provides token pattern matching in a competitive performance for
matching large sets of patterns.
The implementation is maybe not optimal in numbers of reads and writes of memory and in
numbers of branching instructions, but it is software with a good flow. It has
simple operations mainly operating on local (near, on-chip) memory, able to use SIMD capabilities
of modern CPUs and it accesses new (far away) memory mainly for feeding the system.
For users that do not need arbitrary programs to define patterns and for users, that can live with
the restrictions of the model of StrusPattern, the prospect of the performance may be convincing.